
What is Deep Learning?
In simple terms, Deep Learning is a subfield of Artificial Intelligence that tries to imitate the workings of a biological brain. Similar to a brain, in Deep Learning agent or the "brain" contains a nucleus also known as a Deep Learning node, which is connected (theoretically) by Axons, notice that in the parenthesis, I've written "Theoretically", this is because when you write the code for this "Brain", the Axons are represented by multiplying the value in the Nucleus (mostly some floating-point number) by some random number called Weights, the "Learning" portion of Deep Learning consists of finding those values of Weights at which the Inputs can be transformed to the desired output.
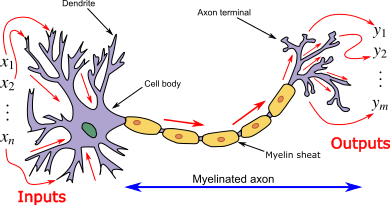
These multiple neurons working together make a layer and when we add multiple layers then we can approximate any mathematical model given enough data and learning time. When a code contains 2 or more layers, then that is Deep Learning.
Deep Learning is a special case of Machine Learning. The logic used in Machine Learning is kinda like a regular program which is a way to get computers to complete a specific task.
Normally, it's easy for programmers to write each case and tell the computer what to do. But in the case of Machine Learning, we don't really know what to expect, the number of variables can be, in some cases, be more than a million. Hence, it doesn't make any sense to write millions of if-else block just to determine if a given photo is of a cat or a dog.
Neural Networks
A Neural Network is like any function, which takes some input X and returns some output Y but the actual in that function is just take the input, multiply that with some number (called weights) and then pass it through some mathematical function that gives of results that is similar to Y.
Weights and Biases
The basic idea of Weights and Biases comes from the mathematical equation
where x is the input such as images of cats, y is the predicted output such as if a given image is a cat or not. Until now, it's pretty straight forward, in order to understand the role of m and c, that is, the slope and the y-intercept, in the learning process, we have to go all the way back to the era where the future prediction was done using statistical methods such as Linear Regression or Logistic Regression.
Let's say you need to predict a person's Weight using that person's BMI (Body Mass Index) then you might plot the data in a graph and draw a line through it such that the error is minimum. Which looks like this.
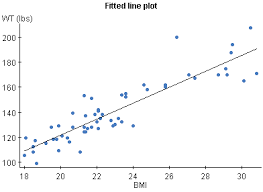
As you can see this line has some slope, m and some y-intercept, c. This logic applied to neural networks where the input vector is multiplied with some Weight vector (slope) then the Bias vector (y-intercept) is added to it.
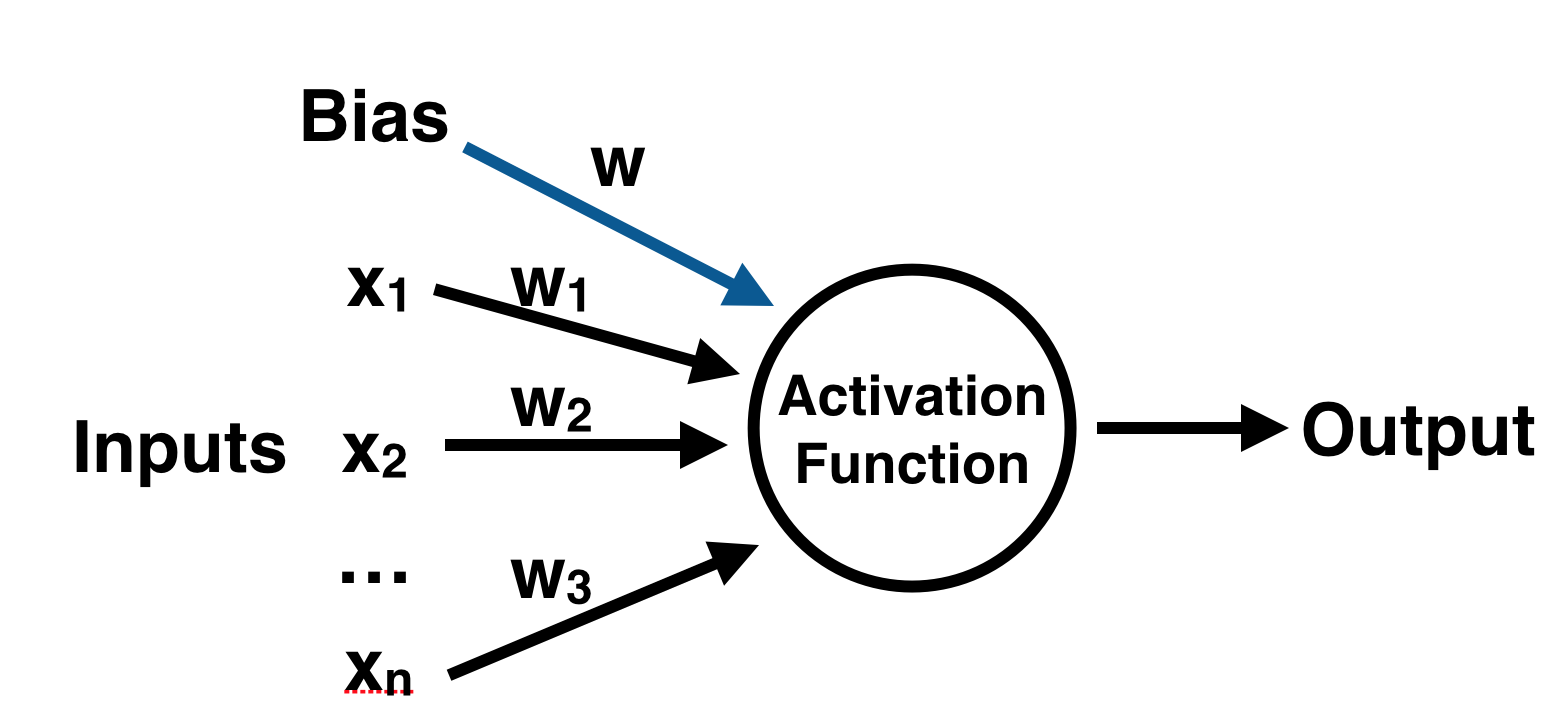
Activation Function
In the above image, you can see the after Input is combined with Weights and Bias, the result goes into an activation function. Now, what is an Activation Function?
In simple terms, it's just some function that converts the predicted output (XW + B) to a format that we need. Such is "Yes, this is a cat" or "No, it's not a cat"
There are 2 kinds of Activation function that you need to use according to the use case.
-
Linear Activation Function It takes the form A = MX and produces outputs that are proportional to the input.
-
Non-Linear Activation Functions Modern neural network models use non-linear activation functions. They allow the model to create complex mappings between the network’s inputs and outputs, which are essential for learning and modelling complex data, such as images, video, audio, and data sets which are non-linear or have high dimensionality.
Loss Function
The Loss Function is one of the important components of Neural Networks. Loss is nothing but a prediction error of Neural Net. And the method to calculate the loss is called Loss Function. In simple words, the Loss is used to calculate the gradients. And gradients are used to update the weights of the Neural Net.
Limitations of Machine Learning and Deep Learning
Contrary to the popular belief that the AI will soon take over humanity, there is some limitation to the current technology of Artificial Intelligence.
-
A model cannot be created without data
-
The model can only learn to operate on the patterns seen in the input data used to train it.
-
This learning approach only creates predictions and not 100% accurate future
-
The input data may be affected by human biases thus the trained model will also contain those biases.
How a model interacts with its environment?
Any machine learning model learns through a feedback loop from the environment, Let's say that you created an AI that plays the game Super Mario Bros. The only thing you programmed was to press A and D key to move left or right and SPACE button to jump. Then you set up two reward system. 1) Your score in the game, which will be a positive reinforcement meaning you need to maximise the score and 2) how many times you get game over screen, which will be negative reinforcement so the AI needs to minimise the number of times it dies.
After that, you just leave the AI to play the game. The model will fist press the buttons randomly and slowly it starts to get feedback from the reward system and the model will eventually learn that Mushrooms in-game is good and Turtles are bad.
One limitation with this learning with feedback loop is that it might magnify the human biases which will then makes News Headlines such as this.
As a Machine Learning Engineer, we need to be careful about how we choose our input data.
That is it for this lesson.